인공지능/머신러닝
연관 규칙(Association Rules)
2^7
2022. 6. 9. 17:06
Association Rules
데이터 사이의 연관된 규칙을 찾는 방법
- 규칙(Rule) - "If 조건 then 결과" 형식
연관 규칙 - 특정 사건 발생 시 함께 자주 발생하는 다른 사건의 규칙(Rule)
지지도(Support)
- 특정 품목 집합이 얼마나 자주 등장하는지 확인
- 특정 품목 집합을 포함하는 거래의 비율로 계산
- 전체 거래에 대한 A와 B가 동시에 발생할 확률
- Support = A와B가동시에포함된거래수/전체거래수
신뢰도(Confidence)
- 상품A가 존재할 때 상품B가 나타나는 빈도
- 상품A가 포함된 거래 중 상품B를 포함한 거래 비율
- 조건(LHS) 발생 시 결과(RHS)가 동시에 일어날 확률
- A가 구매될 때 B가 구매되는 경우의 조건부 확률
- Confidence = A(조건)와B(결과)가동시에포함된거래수/A(조건)를포함한거래수
향상도(Lift)
- 두 물품이 각각 얼마나 자주 거래되는지를 고려
- 상품A와 상품B가 함께 팔리는 빈도
- Lift = Confidence( A → B )/Support( B )
1. Read Data_Set and Preprocessing
DF.head(3)
1-1. 데이터 정보 확인
- DF_1 지정 후 'order_id' 및 'item_name' 종류 확인
- 한 개의 'order_id'가 여러 개의 'item_name'으로 분리되어 지정
DF_1 = DF[['order_id', 'item_name']]
DF_1.order_id.unique().shape, DF_1.item_name.unique().shape((1834,), (50,))
order_ID = list(DF_1.order_id.unique())
order_ID[:10], order_ID[-10:]([1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
[1825, 1826, 1827, 1828, 1829, 1830, 1831, 1832, 1833, 1834])
item_NAME = list(DF_1.item_name.unique())
item_NAME[:5], item_NAME[-5:]
1-2. Preprocessing
orderItems = [[] for i in range(1835)]
len(orderItems)1835
num = 0
for i in DF_1.item_name :
orderItems[DF_1.order_id[num]].append(i)
num = num + 1orderItems[:5], orderItems[-5:]
#첫 번째 빈 리스트 제거 및 중복 아이템 단일화
orderItems.pop(0)
num = 0
for i in orderItems :
orderItems[num] = list(set(orderItems[num]))
num = num + 1orderItems[:5], orderItems[-5:]
2. TransactionEncoder( )
#Transaction 구조 변환
from mlxtend.preprocessing import TransactionEncoder
TSE = TransactionEncoder()
Transac_Array = TSE.fit_transform(orderItems)#pandas DataFrame 구조 변환
order_DF = pd.DataFrame(Transac_Array, columns = TSE.columns_)
order_DF.head()
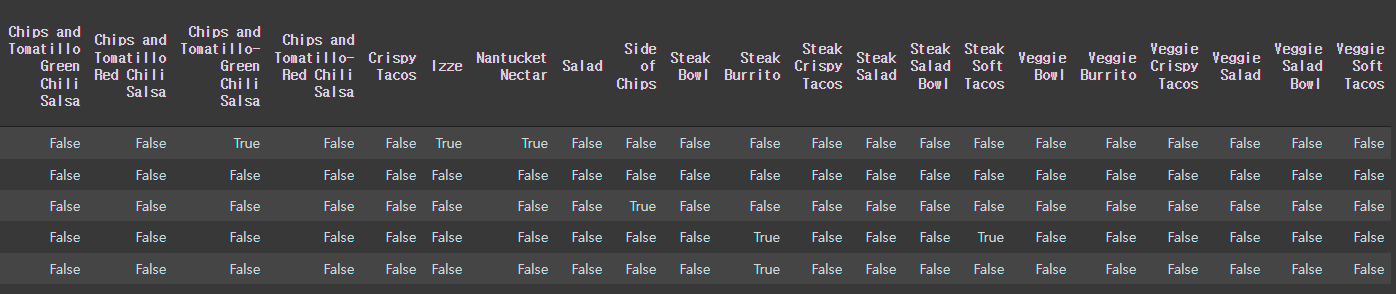
order_DF.shape(1834, 50)
3. apropri( )
- 지지도(support) 0.05 이상인 주문 추출
- use_colnames : item_name으로 출력
- max_len : 주문의 최대 길이 지정
from mlxtend.frequent_patterns import apriori
frequent_itemsets = apriori(order_DF,
min_support = 0.05,
use_colnames = True,
max_len = None)
frequent_itemsets
4. association_rules( )
4-1. 지지도(support)가 최소 0.05 이상인 연관관계 출력
- antecedents(조건절) -> consequents(결과절)
- 전체 주문 중 조건절과 결과절을 포함한 비율
- 방향성 없음
from mlxtend.frequent_patterns import association_rules
association_rules(frequent_itemsets,
metric = 'support',
min_threshold = 0.05)
4-2. 신뢰도(confidence)가 최소 0.3 이상인 연관관계 출력
- 조건절이 있을때 결과절도 있는 비율
- 조건부확률
- 방향성 존재
association_rules(frequent_itemsets,
metric = 'confidence',
min_threshold = 0.3)
4-3. 향상도(support)가 최소 0.1 이상인 연관관계 출력
- 향상도가 1이라면 조건절과 결과절은 독립관계
- 1보다 크거나 작다면 우연이 아닌 필연적 관계
association_rules(frequent_itemsets,
metric = 'lift',
min_threshold = 0.1)
728x90