고정 헤더 영역

상세 컨텐츠
본문
다중회귀분석(Multivariate Regression)
import pandas as pd
url = 'https://raw.githubusercontent.com/rusita-ai/pyData/master/Insurance.csv'
DF = pd.read_csv(url)
DF.info()
1. 탐색적 데이터 분석
import matplotlib.pyplot as plt
import seaborn as sns1-1. 전체 의료비 분포
plt.figure(figsize = (9, 6))
sns.distplot(DF.expenses,
hist = True,
kde = True)
plt.show()
plt.figure(figsize = (9, 6))
sns.boxplot(y = 'expenses', data = DF)
plt.show()
1-2. 성별 별 의료비 분포
plt.figure(figsize = (9, 6))
sns.boxplot(x = 'sex', y = 'expenses', data = DF)
plt.show()
DF.sex.value_counts()male 676
female 662
Name: sex, dtype: int64
1-3. 자녀수 별 의료비 분포
plt.figure(figsize = (9, 6))
sns.boxplot(x = 'children', y = 'expenses', data = DF)
plt.show()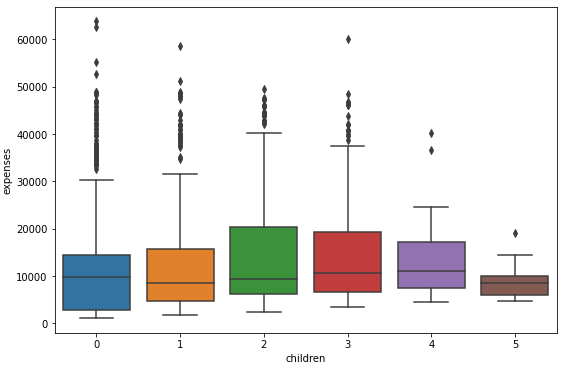
DF.children.value_counts()
1-4. 흡연여부 별 의료비 분포
plt.figure(figsize = (9, 6))
sns.boxplot(x = 'smoker', y = 'expenses', data = DF)
plt.show()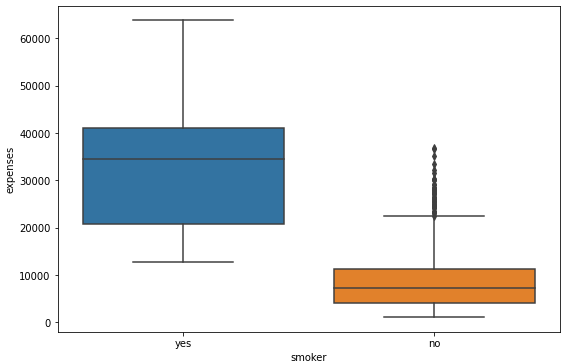
DF.smoker.value_counts()no 1064
yes 274
Name: smoker, dtype: int64
1-5. 거주지역 별 의료비 분포
plt.figure(figsize = (9, 6))
sns.boxplot(x = 'region', y = 'expenses', data = DF)
plt.show()
DF.region.value_counts()
1-6. BMI 분포 및 의료비와의 관계
# BMI 분포
plt.figure(figsize = (9, 6))
sns.distplot(DF.bmi,
hist = True,
kde = True)
plt.show()
# BMI와 의료비 간의 관계
plt.figure(figsize = (9, 6))
sns.scatterplot(x = DF.bmi, y = DF.expenses)
plt.show()
2. Modeling
2-1. Integer Encoding
- LabelEncoder( )
- 'sex', 'smoker', 'region' to int64
from sklearn.preprocessing import LabelEncoder
encoder1 = LabelEncoder()
DF['sex'] = encoder1.fit_transform(DF.sex)encoder2 = LabelEncoder()
DF['smoker'] = encoder2.fit_transform(DF.smoker)encoder3 = LabelEncoder()
DF['region'] = encoder3.fit_transform(DF.region)DF.head()
2-2. Train & Test Array Split(7:3)
from sklearn.model_selection import train_test_split
X = DF[['age', 'sex']]
y = DF['expenses']
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.3,
random_state = 2045)
print('Train Data : ', X_train.shape, y_train.shape)
print('Test Data : ', X_test.shape, y_test.shape)Train Data : (936, 2) (936,)
Test Data : (402, 2) (402,)
2-3. fit()
from sklearn.linear_model import LinearRegression
RA = LinearRegression()
RA.fit(X_train, y_train)LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
2-4. .predict( )
y_hat = RA.predict(X_test)2-5. 오차(Error)값 확인
- Mean Sqaured Error - sklearn
from sklearn.metrics import mean_squared_error
import numpy as np
mse2 = mean_squared_error(y_test, y_hat)
np.sqrt(mse2)10633.607635499553
3. Modeling
import pandas as pd
url = 'https://raw.githubusercontent.com/rusita-ai/pyData/master/Insurance.csv'
DF = pd.read_csv(url)
DF.info()3-1. Data Preprocessing
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(DF,
test_size = 0.3,
random_state = 2045)
train_set.shape, test_set.shape((936, 7), (402, 7))
train_set.info()
3-2. expenses ~ age + sex
- train_set으로 모델 생성
- OLS(최소자승법) : Ordinary Least Squares
import statsmodels.formula.api as smf
Model_1 = smf.ols(formula = 'expenses ~ age + sex',
data = train_set).fit()3-3. y_hat 생성
- test_set으로 y_hat(예측값) 계산
y_hat_1 = Model_1.predict(test_set[['age', 'sex']])3-4.오차(Error)값 확인
- Mean Sqaured Error - sklearn
mse1 = mean_squared_error(test_set.expenses, y_hat_1)
np.sqrt(mse1)10633.607635499555
4. Package별 오차값 비교
print('statsmodels :', np.sqrt(mse1))
print('sklearn :', np.sqrt(mse2))statsmodels : 10633.607635499555
sklearn : 10633.607635499553
728x90
'인공지능 > 머신러닝' 카테고리의 다른 글
| 로지스틱 회귀(Logistic Regression) 2 (0) | 2022.06.07 |
|---|---|
| 로지스틱 회귀(Logistic Regression) 1 (0) | 2022.06.07 |
| 회귀분석(Regression Analysis) 3 (1) | 2022.06.07 |
| 회귀분석(Regression Analysis) 2 (0) | 2022.06.07 |
| 회귀분석(Regression Analysis) 1 (1) | 2022.06.07 |




