고정 헤더 영역

상세 컨텐츠
본문
from google.colab import drive
drive.mount('/content/drive')
1. YOLOv3 Weight Download
1-1. 'yolov3.weights'
from urllib.request import urlretrieve
urlretrieve('https://pjreddie.com/media/files/yolov3.weights','yolov3.weights')('yolov3.weights', <http.client.HTTPMessage at 0x7fe9928e0b50>)
1-2. 'yolov3-tiny.weights'
from urllib.request import urlretrieve
urlretrieve('https://pjreddie.com/media/files/yolov3-tiny.weights','yolov3-tiny.weights')('yolov3-tiny.weights', <http.client.HTTPMessage at 0x7fe992250a10>)
2. darknet Clone
!git clone https://github.com/pjreddie/darknet.git
2-1. 'yolov3.cfg'
!cat darknet/cfg/yolov3.cfg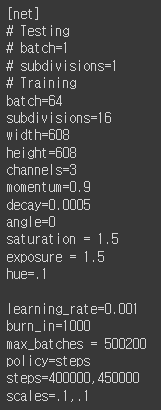

검출 하고자 하는 classes의 수에 따라 filters, classes의 값을 변경해야 한다.
2-2. 'yolov3-tiny.cfg'
!cat darknet/cfg/yolov3-tiny.cfg2-3. 'coco.names'
!cat darknet/data/coco.names- 80가지 객체

3. Image
3-1. Import Packages
import cv2
from google.colab.patches import cv2_imshow
import numpy as np3-2. 'Detection' 최소 신뢰도(확률) 지정
min_confidence = 0.53-3. Load YOLOv3
net = cv2.dnn.readNet('yolov3.weights', 'darknet/cfg/yolov3.cfg')
# net = cv2.dnn.readNet('yolov3-tiny.weights', 'darknet/cfg/yolov3-tiny.cfg')
# Detection된 Object(Class) List 배열 정의
classes = []
# 80개의 Object(class)를 구분할 수 있는 Object의 이름을 classes 배열에 넣어준다.
with open('darknet/data/coco.names', 'r') as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# Object 마다 컬러를 하나씩 다르게 지정
colors = np.random.uniform(0, 255, size=(len(classes), 3))3-4. 원본 Image
img = cv2.imread('/content/drive/My Drive/Colab Notebooks/datasets/testImage.jpeg')
img = cv2.resize(img, None, fx = 0.8, fy = 0.8)
height, width, channels = img.shape
cv2_imshow(img)
3-5. Image Object Detection
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop = False)
net.setInput(blob)
outs = net.forward(output_layers)class_ids = [] # Detection Class_ID 저장
confidences = [] # Detection Class_신뢰도(확률) 저장
boxes = [] # Detection Boxing_정보 저장
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores) # Detected Class_ID
confidence = scores[class_id] # Detected Class_신뢰도(확률)
if confidence > min_confidence:
# Object Detected
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# Rectangle Coordinates
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h]) # Boxing_정보 추가
confidences.append(float(confidence)) # 신뢰도(확률) 추가
class_ids.append(class_id) # Class_ID 추가indexes = cv2.dnn.NMSBoxes(boxes, confidences, min_confidence, 0.4)
font = cv2.FONT_HERSHEY_PLAIN
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(classes[class_ids[i]])
print(i, label)
color = colors[i]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 1)
cv2.rectangle(img, (x, y - 20), (x + w, y), color, -1)
cv2.putText(img, label, (x + 5, y - 5), font, 1, (255, 255, 255), 1)
cv2_imshow(img)
3 car 4 car 5 person 6 car 7 car 8 car 9 car 10 bicycle

4. Video
4-1. Import Packages
import cv2
import numpy as np
import time
import io
import base64
from IPython.display import HTML4-2. 원본 Video
video = io.open('/content/drive/My Drive/Colab Notebooks/datasets/testVideo.mp4', 'r+b').read()
encoded = base64.b64encode(video)
HTML(data='''<video width="70%" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4"/>
</video>'''.format(encoded.decode('ascii')))4-3. 탐색 정보
file_name = '/content/drive/My Drive/Colab Notebooks/datasets/testVideo.mp4'
min_confidence = 0.5
output_name = 'testVideo_output.mp4'
elapsed_time = 0def detectAndDisplay(frame):
start_time = time.time()
img = cv2.resize(frame, None, fx = 0.8, fy = 0.8)
height, width, channels = img.shape
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
# Showing Informations
class_ids = [] # Class_ID 저장
confidences = [] # Class_신뢰도(확률) 저장
boxes = [] # Boxing_정보 저장
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores) # Detected Class_ID
confidence = scores[class_id] # Detected Class_신뢰도(확률)
if confidence > min_confidence:
# Object Detected
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# Rectangle Coordinates
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h]) # Boxing_정보 추가
confidences.append(float(confidence)) # 신뢰도(확률) 추가
class_ids.append(class_id) # Class_ID 추가
indexes = cv2.dnn.NMSBoxes(boxes, confidences, min_confidence, 0.4)
font = cv2.FONT_HERSHEY_PLAIN
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = "{}: {:.2f}".format(classes[class_ids[i]], confidences[i]*100)
print(i, label)
color = colors[1] ###
cv2.rectangle(img, (x, y), (x + w, y + h), color, 1)
cv2.rectangle(img, (x, y - 20), (x + w, y), color, -1)
cv2.putText(img, label, (x + 5, y - 5), font, 1, (255, 255, 255), 1)
process_time = time.time() - start_time
global elapsed_time
elapsed_time += process_time
print("=== A frame took {:.3f} seconds".format(process_time))
# 결과 Video 저장
global writer
if writer is None and output_name is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(output_name, fourcc, 30,
(img.shape[1], img.shape[0]), True)
if writer is not None:
writer.write(img)4-4. Load YOLOv3
net = cv2.dnn.readNet('yolov3.weights', 'darknet/cfg/yolov3.cfg')
classes = []
with open('darknet/data/coco.names', 'r') as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# colors = np.random.uniform(0, 255, size=(len(classes), 3))
cap = cv2.VideoCapture(file_name)
writer = None
if not cap.isOpened:
print('--(!)Error opening video capture')
exit(0)
while True:
ret, frame = cap.read()
if frame is None:
cap.release()
writer.release()
print('--(!) No captured frame -- Break!')
print("elapsed time {:.3f} seconds".format(elapsed_time))
break
detectAndDisplay(frame)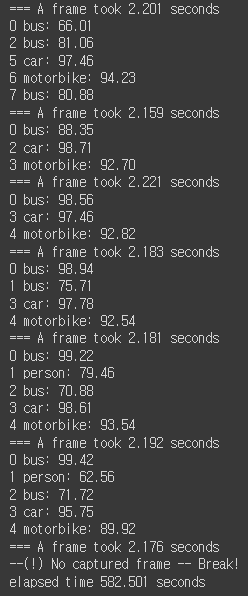
728x90
'인공지능 > 딥러닝' 카테고리의 다른 글
| YOLOv3 Object Detection 1 (0) | 2022.07.04 |
|---|---|
| Top_5_Correctness (0) | 2022.07.04 |
| CNN(Convolutional Neural Network)-CIFAR 100_ResNet50V2 (0) | 2022.07.04 |
| CNN(Convolutional Neural Network)-CIFAR 10_Functional API Modeling (0) | 2022.06.29 |
| CNN 모델 학습 시각화 (0) | 2022.06.28 |




